un changement de paradigme dans l’architecture des données
Les avancées technologiques, l’accroissement des exigences des entreprises et les réglementations (telles que RGPD et CCPA) sont des moteurs importants de l’évolution de l’architecture des données.
Aujourd’hui différents modèles et schémas d’architecture sont mis en œuvre :
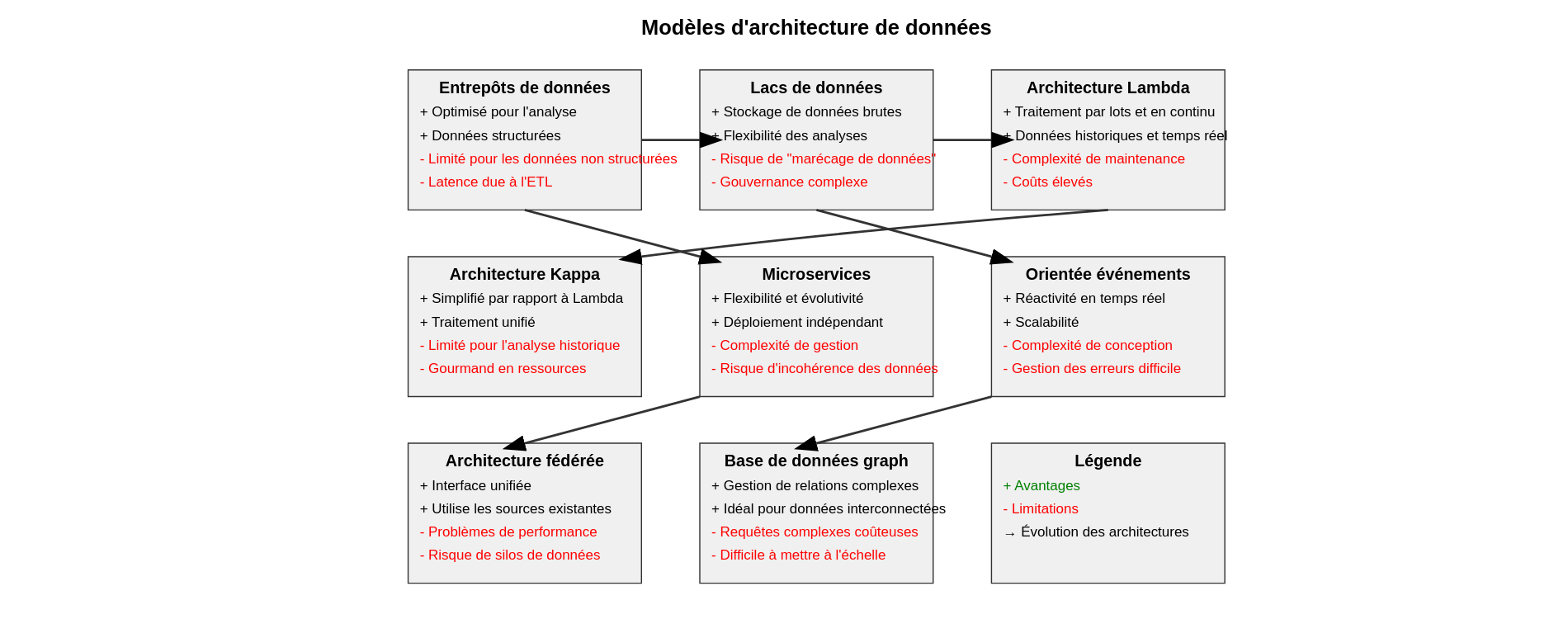
Entrepôts de données traditionnels
Des référentiels centralisés pour les données structurées, optimisés pour les requêtes analytiques et les rapports. Les entrepôts de données suivent généralement une approche de schéma d’écriture, dans laquelle les données sont structurées et transformées avant d’être chargées dans l’entrepôt. Les entrepôts de données traditionnels les plus populaires sont Oracle Exadata, IBM Netezza et Teradata.
Limites :
- Des volumes massifs de données générés par les applications
- Difficultés pour l’adaptation à des formats de données semi–structurés ou non-structurés
- Les processus ETL peuvent introduire une latence, ce qui rend complexe la fourniture d’informations en temps réel
Lacs de données
Référentiels centralisés qui stockent des données brutes, non structurées ou semi structurées à grande échelle. Contrairement aux entrepôts de données, les lacs de données permettent aux organisations de stocker les données dans leur format d’origine et d’effectuer divers types d’analyses, notamment l’analyse exploratoire, l’apprentissage automatique et les requêtes ad hoc. Les technologies populaires pour la création de lacs de données incluent Apache Hadoop, Apache Spark et Amazon S3.
Limites :
- Sans une gouvernance adéquate, les data lakes peuvent se transformer en marécages de données, rendant difficile la recherche et la confiance dans les données pertinentes.
- La gestion et l’organisation d’un grand volume de données brutes dans un data lake nécessitent une planification minutieuse et une gestion des métadonnées.
- Stocker des données brutes sans prétraitement peut entraîner des problèmes de qualité des données, nécessitant des efforts supplémentaires pour le nettoyage et la transformation.
Architecture Lambda
Approche hybride qui combine le traitement par lots et le traitement en continu pour gérer à la fois les données historiques et les données en temps réel. Elle se compose généralement de trois couches :
- Une couche par lots pour stocker et traiter les données historiques,
- Une couche de vitesse pour gérer les données en temps réel,
- Une couche de service pour interroger et servir les résultats.
Apache Kafka, Apache Hadoop et Apache Spark sont couramment utilisés dans les architectures Lambda.
Limites :
- Mettre en œuvre et maintenir des couches par lots et de vitesse séparées peut introduire de la complexité dans l’architecture.
- Assurer la cohérence entre les couches par lots et de vitesse peut être difficile et peut nécessiter des mécanismes de synchronisation supplémentaires.
- La gestion de plusieurs couches et technologies augmente la surcharge opérationnelle et les coûts de maintenance.
Architecture Kappa
Une version simplifiée de l’architecture Lambda qui utilise exclusivement le traitement de flux pour les données en temps réel et par lots. Elle élimine le besoin de couches de traitement distinctes, ce qui se traduit par une architecture plus rationalisée et évolutive.
Limites :
- Puisque l’architecture Kappa repose principalement sur le traitement de flux, l’analyse des données historiques peut être limitée par rapport à l’architecture Lambda.
- Le traitement de toutes les données en temps réel peut être gourmand en ressources et peut nécessiter une infrastructure évolutive pour gérer les charges de travail maximales.
Architecture de microservices
La décomposition des applications en petits services indépendants qui peuvent être développés, déployés et mis à l’échelle de manière indépendante. Chaque micro service a généralement sa propre base de données, et les données sont échangées entre les services via des API. L’architecture de microservices offre flexibilité, évolutivité et résilience, mais elle introduit également des défis liés à la cohérence et à la gestion des données.
Limites :
- Maintenir la cohérence des données entre plusieurs microservices peut être difficile, surtout dans les systèmes distribués.
- La gestion d’un grand nombre de microservices introduit une complexité opérationnelle, notamment en ce qui concerne le déploiement, la surveillance et le débogage.
- La Duplication des données entre plusieurs microservices induit des risques d’incohérence et des problèmes de synchronisation.
Architecture orientée événements :
L’architecture orientée événements repose sur la production, la détection, la consommation et la réaction aux événements. Les événements sont générés par diverses sources et peuvent déclencher des actions en temps réel. Les architectures orientées événements conviennent parfaitement aux scénarios nécessitant une réactivité et une évolutivité.
Limites :
- Concevoir des systèmes orientés événements est complexe et nécessite une réflexion approfondie sur la source des événements, leur distribution et leur cohérence finale.
- La gestion et le traitement des événements en temps réel introduisent des complexités en matière de gestion des erreurs et de récupération.
- Mettre à l’échelle les architectures orientées événements pour gérer de grands volumes d’événements nécessite une infrastructure robuste et des capacités de surveillance.
Architecture fédérée
Les données restent décentralisées à travers plusieurs systèmes ou emplacements, mais elles sont accessibles via une interface unifiée. Cette approche permet aux organisations de tirer parti des sources de données existantes sans centraliser le stockage des données.
Limites :
- Accéder aux données à partir de plusieurs sources peut introduire des problèmes de latence et de performance, en particulier pour les requêtes complexes.
- Les architectures fédérées peuvent perpétuer les silos de données si elles ne sont pas conçues et mises en œuvre correctement, limitant le partage et l’intégration des données.
- Les architectures fédérées peuvent introduire des défis en matière de sécurité, en particulier en ce qui concerne les contrôles d’accès aux données et les mécanismes d’authentification.
Architecture de base de données graph
Les données sont représentées sous forme de nœuds, d’arêtes et de propriétés, ce qui les rend bien adaptées à la gestion de relations complexes et de données interconnectées. Les architectures de base de données graph sont couramment utilisées dans des applications telles que les réseaux sociaux, les moteurs de recommandation et les systèmes de détection de fraude.
Limites :
- Les requêtes complexes traversant de grands graphiques peuvent être coûteuses en termes de calcul et peuvent nécessiter des techniques d’optimisation.
- Concevoir un modèle de données graphique efficace nécessite une réflexion minutieuse sur les relations et la structure des données.
- Mettre à l’échelle les bases de données graphiques pour gérer de grands graphiques avec des millions de nœuds et d’arêtes peut être difficile.
Comme on peut le voir à travers cette analyse macro, les modèles traditionnels rencontrent des obstacles à leur évolution en raison de l’augmentation constante en volume et en complexité des données. De plus, les architectures centralisées entraînent souvent la création de silos de données et de goulots d’étranglement, entravant ainsi l’accessibilité et la collaboration au sein de l’organisation. Par ailleurs, appliquer des politiques de gouvernance des données cohérentes à l’échelle de toute l’organisation peut s’avérer être un défi pour ces architectures centralisées. En outre, ces modèles sont vulnérables aux points de défaillance uniques et peuvent avoir du mal à maintenir la disponibilité des données en cas de perturbations. Face à ces défis, quel type d’architecture peut efficacement surmonter ces limitations ?
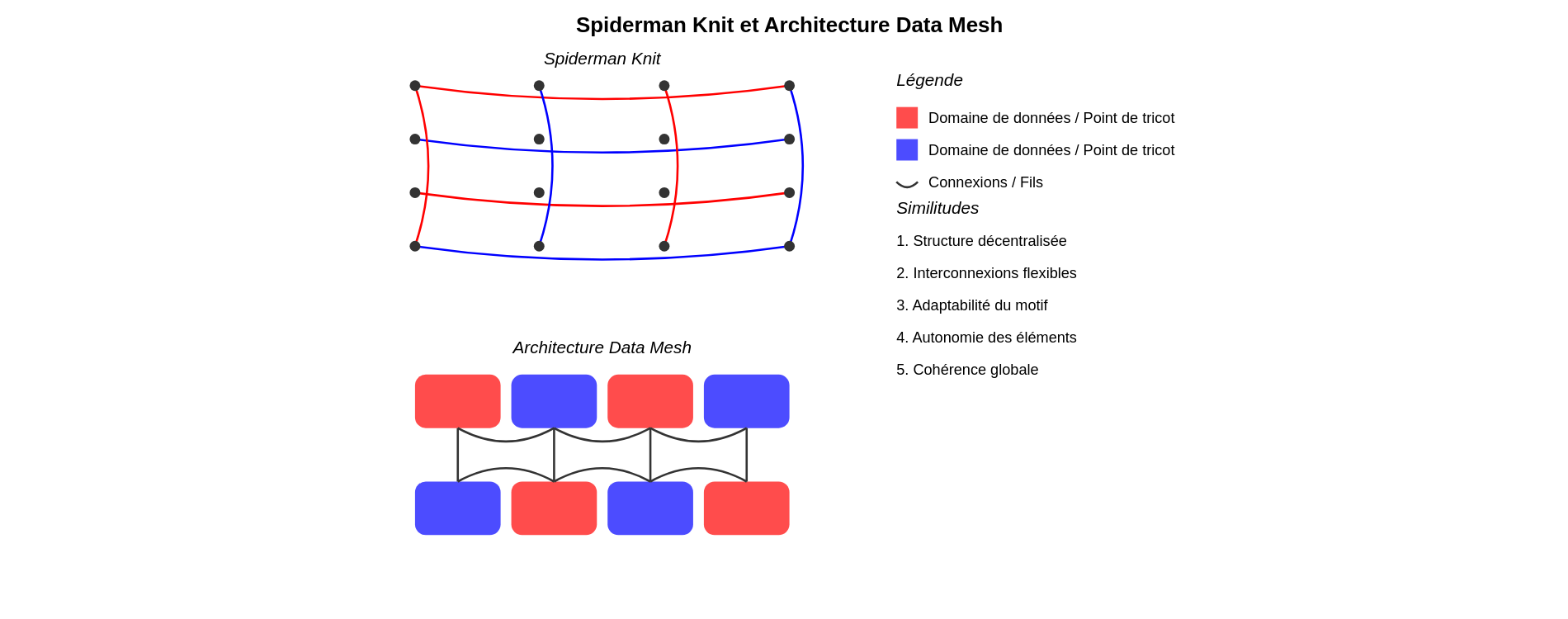
Spiderman Knit et architecture Data Mesh
« Spiderman Knit » évoque un style de tricot ou une technique utilisée pour concevoir un tissu rappelant les toiles d’araignées ou le costume de Spiderman. Cette technique implique l’utilisation de boucles ou de points entrelacés pour créer une texture ressemblant à la structure complexe associée au super-héros. Le tricot Spiderman consiste à travailler simultanément sur différentes parties du tissu pour créer un motif, plutôt que d’adopter une approche centralisée. Les modèles de tricot Spiderman varient en complexité et en design, offrant ainsi une grande flexibilité et adaptabilité. Cette description met en lumière les caractéristiques interconnectées, décentralisées et adaptables du « Spiderman Knit ».
En analogie, considérons la distribution des données entre des domaines spécifiques, chacun étant responsable de ses propres produits et services de données. Tout comme les fils entrelacés d’un tricot Spiderman forment un motif cohérent, cette architecture repose sur des produits et services de données interconnectés pour répondre aux besoins en données de l’organisation. En adoptant une approche décentralisée de la propriété et de la gestion des données, les équipes spécifiques à un domaine peuvent prendre en charge leurs propres données et créer des produits de données adaptés à leurs besoins. Cette approche décentralisée favorise l’agilité, la scalabilité et l’innovation, tout comme la flexibilité et la créativité nécessaires à la conception d’un motif inspiré de Spiderman. Cette architecture peut s’adapter à diverses sources de données, formats et cas d’utilisation, permettant ainsi aux organisations d’ajuster leur infrastructure de données selon leurs besoins spécifiques.
Il s’agit de l’architecture DATA MESH, basée sur des principes fondamentaux qui favorisent la décentralisation, l’interopérabilité et l’autonomie des domaines de données.
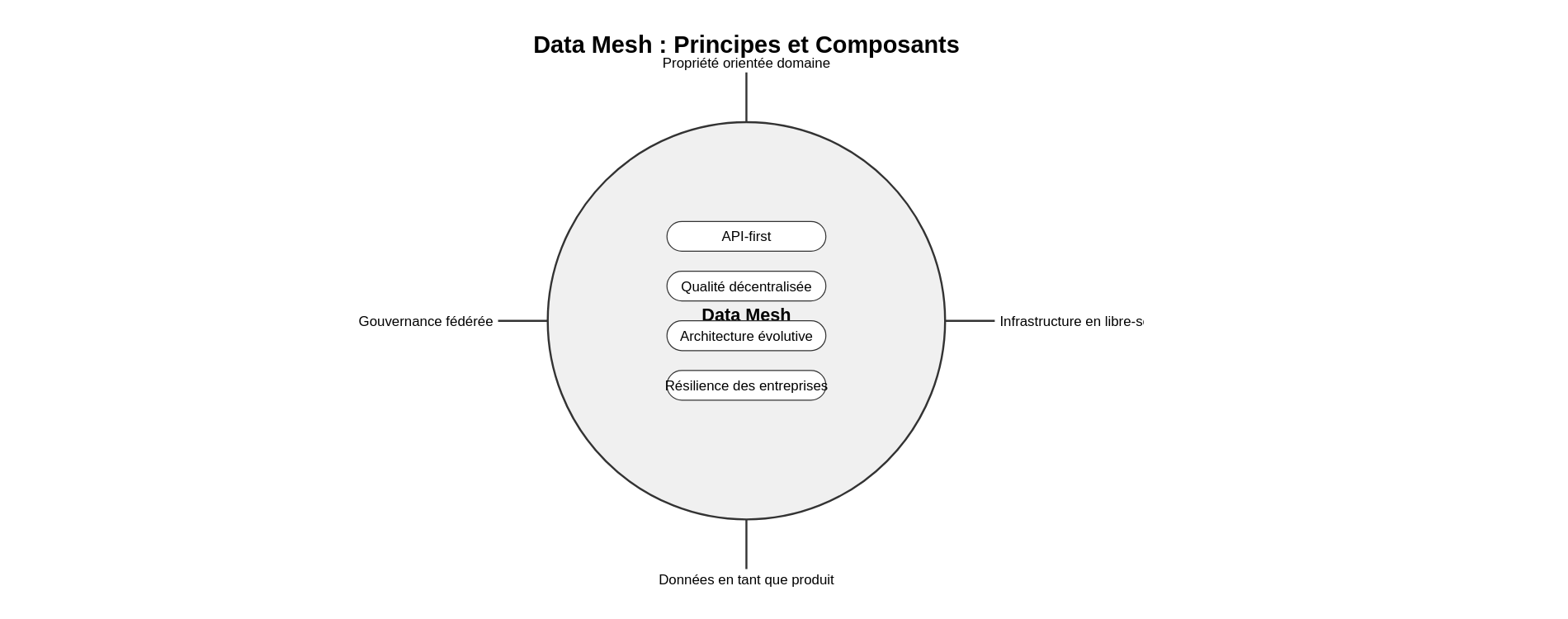
Principes de base
Les bases fondamentales du maillage de données sont posées pour guider son élaboration et son déploiement. Ils sont élaborés pour répondre aux défis des architectures de données centralisées traditionnelles et promouvoir une approche décentralisée et axée sur les domaines dans la gestion des données.
- Propriété des données orientée domaine : La propriété et la gouvernance des données sont décentralisées, avec les équipes spécifiques à un domaine prenant en charge les données qu’elles produisent et utilisent. Chaque équipe de domaine est chargée de définir et de gérer ses propres produits et services de données.
- Infrastructure de données en libre-service : Les équipes de domaine bénéficient d’un accès en libre-service à l’infrastructure et aux outils de données, ce qui leur permet de créer, déployer et exploiter de manière autonome des produits de données. Cette approche réduit les dépendances à l’égard des équipes de données centralisées et favorise l’agilité et l’autonomie.
- Les données en tant que produit : Les données sont considérées comme un produit, produit, consommé et amélioré par les équipes du domaine. Ce changement de perspective encourage les équipes de domaine à se concentrer sur la création de valeur à travers leurs produits et services de données, de la même manière que pour les produits logiciels.
- Architecture et plateforme de maillage de données : L’organisation investit dans la mise en place d’une architecture et d’une plateforme de maillage de données qui fournissent l’infrastructure, les outils et les normes nécessaires pour aider les équipes de domaine à gérer leurs produits de données. Cela comprend des fonctionnalités telles que la découverte de données, la gestion des métadonnées et la gouvernance des données.
- Gouvernance des données fédérée : La gouvernance des données est fédérée, avec les équipes de domaine chargées de définir et de mettre en œuvre des politiques de gouvernance adaptées à leurs besoins spécifiques. Cela permet aux équipes du domaine de conserver leur autonomie tout en assurant le respect des normes et réglementations organisationnelles.
- Réflexion produit et conception centrée sur l’utilisateur : Les équipes de domaine adoptent une approche de réflexion produit et des principes de conception centrés sur l’utilisateur pour développer des produits de données répondant aux besoins de leurs utilisateurs. Cela implique de comprendre les besoins des utilisateurs, d’itérer en fonction des retours d’expérience et de prioriser les fonctionnalités offrant le plus de valeur.
- Approche API-first : Les produits de données exposent des API qui permettent à d’autres équipes du domaine de découvrir, d’accéder et d’intégrer des données de manière standardisée et interopérable. Cela favorise la réutilisabilité, l’interopérabilité et la collaboration entre les domaines.
- Qualité décentralisée et observabilité des données : Les équipes de domaine sont responsables d’assurer la qualité, la fiabilité et l’observabilité de leurs produits de données. Cela implique la mise en place de contrôles de qualité des données, la surveillance des pipelines de données et la fourniture d’une visibilité sur l’utilisation et les performances des données;
- Architecture évolutive et amélioration continue : L’architecture de maillage de données est conçue pour évoluer au fil du temps en réponse à l’évolution des besoins de l’entreprise et aux avancées technologiques. Les équipes de domaine sont encouragées à expérimenter, à itérer et à améliorer continuellement leurs produits et infrastructures de données.
En adhérant à ces principes fondamentaux, les organisations peuvent bénéficier des avantages d’une approche décentralisée et orientée vers les domaines de la gestion des données, comme une agilité, une évolutivité et une innovation accrues, tout en surmontant les défis des architectures de données centralisées tels que les silos de données, la complexité et les limitations de l’évolutivité.
Vers la résilience des entreprises et la convergence des données
En adoptant les principes du Data Mesh, les organisations peuvent renforcer la résilience de leur entreprise en décentralisant la propriété des données, en autorisant des capacités en libre-service, en instaurant une gouvernance fédérée, en adoptant une approche centrée sur les API, en mettant en place une architecture évolutive et en encourageant une culture axée sur la réflexion concernant les produits de données.
Voici comment :
1. Propriété décentralisée des données :
En décentralisant la propriété des données, le Data Mesh permet à chaque équipe de domaine de gérer ses propres produits de données. Cette approche réduit les dépendances envers les équipes et les systèmes centralisés, renforçant ainsi la résilience de l’organisation face aux perturbations. En cas de problème dans un domaine, les autres domaines peuvent continuer à fonctionner de manière autonome, limitant ainsi l’impact sur l’ensemble de l’entreprise.
2. Infrastructure de données en libre-service
Dans le cadre du Data Mesh, l’accès en libre-service à l’infrastructure de données et aux outils est encouragé pour les équipes de domaine. Cette approche permet aux équipes d’ajuster rapidement leurs produits et infrastructures de données en fonction des besoins évolutifs de l’entreprise, sans avoir à dépendre de ressources centralisées. Les capacités de libre-service améliorent l’agilité et permettent une réaction plus rapide aux perturbations, ce qui aide l’entreprise à maintenir ses opérations pendant les périodes difficiles.
3. Gouvernance fédérée :
Avec une approche de gouvernance fédérée, chaque équipe de domaine est chargée de définir et de mettre en œuvre des politiques de gouvernance adaptées à ses besoins spécifiques. Cela garantit la conformité aux réglementations et aux normes organisationnelles tout en répondant aux diverses exigences commerciales. La gouvernance fédérée réduit les goulots d’étranglement et renforce la capacité de l’organisation à s’adapter aux changements ou aux perturbations réglementaires.
4. Approche API-First :
Dans le cadre du Data Mesh, une approche API-First est encouragée pour l’intégration des données, facilitant ainsi l’échange et l’accès aux données entre différents systèmes et équipes. Les API fournissent des interfaces standardisées pour le partage de données, favorisant une intégration et une interopérabilité transparentes entre les produits de données. Cette approche facilite la collaboration et permet à l’entreprise d’ajuster rapidement ses processus et systèmes en réponse aux perturbations ou aux nouvelles exigences.
5. Architecture évolutive :
L’architecture Data Mesh est conçue pour évoluer en fonction des besoins changeants de l’entreprise et des progrès technologiques. Les équipes de domaine sont encouragées à expérimenter, à itérer et à améliorer en permanence leurs produits et leurs infrastructures de données. Cette approche évolutive favorise l’innovation et l’adaptabilité, assurant ainsi que l’organisation reste résiliente face aux défis et aux opportunités évolutifs.
6. Pensée produit de données :
En traitant les données comme un produit, les équipes de domaine sont incitées à se concentrer sur la création de valeur pour leurs utilisateurs. Ce changement de mentalité favorise une conception centrée sur l’utilisateur, une itération rapide et une amélioration continue des produits de données. En fournissant des produits de données précieux qui répondent aux besoins des utilisateurs, l’organisation peut mieux résister aux perturbations et maintenir sa résilience. Ces principes permettent aux équipes de s’adapter rapidement aux perturbations, aux changements réglementaires et à l’évolution des exigences commerciales, garantissant ainsi que l’organisation reste résiliente et compétitive dans un environnement en évolution rapide.
Défis d’adoption
Si l’architecture de maillage de données offre de nombreux avantages, son adoption s’accompagne de plusieurs défis auxquels les organisations peuvent être confrontées.
- Changement culturel : les architectures de données centralisées traditionnelles impliquent souvent un contrôle et une prise de décision centralisés, alors qu’un maillage de données favorise la décentralisation et l’autonomie entre les équipes du domaine. Convaincre les parties prenantes et les équipes d’adopter ce changement culturel peut s’avérer difficile et peut nécessiter un leadership fort et des efforts de gestion du changement.
- Compétences et expertises : l’adoption d’une architecture de maillage de données nécessite que les équipes du domaine possèdent les compétences et l’expertise nécessaires dans des domaines tels que l’ingénierie des données, la gouvernance des données et la gestion des produits. Les organisations devront peut-être investir dans des initiatives de formation et de perfectionnement pour garantir que les équipes du domaine disposent des capacités nécessaires pour gérer efficacement leurs produits de données.
- Complexité technologique : la mise en œuvre d’une architecture de maillage de données implique le déploiement et la gestion d’un ensemble diversifié de technologies, notamment une infrastructure de données, des outils et des plateformes. L’intégration de ces technologies et la garantie de l’interopérabilité peuvent s’avérer complexes et nécessiter un investissement initial important dans l’infrastructure et l’expertise.
- Gouvernance et sécurité des données : la décentralisation de la propriété des données soulève des défis liés à la gouvernance, à la sécurité et à la conformité des données. Garantir des politiques de gouvernance et des contrôles de sécurité cohérents entre les équipes de domaine tout en permettant flexibilité et autonomie peut s’avérer difficile. Les organisations doivent établir des cadres de gouvernance et des mesures de sécurité robustes pour atténuer les risques associés à la gestion décentralisée des données.
- Qualité et cohérence des données : maintenir la qualité et la cohérence des données entre les équipes du domaine peut s’avérer difficile, en particulier lorsque les données proviennent de systèmes et de sources disparates. Garantir la qualité, la fiabilité et la cohérence des données tout en permettant l’autonomie et la flexibilité nécessite une planification, une surveillance et une collaboration minutieuses entre les équipes du domaine.
- Intégration et interopérabilité : garantir une intégration et une interopérabilité transparentes tout en permettant l’autonomie et l’accès en libre-service nécessite des API, des formats de données et des protocoles de communication standardisés. Les organisations doivent investir dans des technologies et des pratiques d’intégration pour faciliter l’échange de données et la collaboration.
- Silos organisationnels : les équipes de domaine peuvent se concentrer trop sur leurs propres produits et priorités en matière de données, ce qui entraîne une fragmentation et une duplication des efforts. Les organisations doivent favoriser la collaboration et la communication entre les équipes de domaine pour garantir l’alignement avec les objectifs commerciaux plus larges.
- Gestion du changement : la transition vers une architecture de maillage de données implique des changements organisationnels importants et peut se heurter à la résistance des parties prenantes habituées aux approches centralisées traditionnelles. Une gestion efficace du changement, une communication et un engagement des parties prenantes sont essentiels pour surmonter la résistance et garantir l’adoption réussie de l’architecture de maillage de données.
Relever ces défis nécessite une approche globale qui implique d’aligner la culture organisationnelle, de développer les compétences et l’expertise nécessaires, de mettre en œuvre des mesures de gouvernance et de sécurité solides, de favoriser la collaboration et la communication et de gérer efficacement le changement.
Conclusion : potentiel transformateur du maillage de données dans la refonte de l’architecture des données
En résumé, l’architecture de maillage de données responsabilise les équipes de domaine, favorise la collaboration et assure une évolution synchronisée des données avec les besoins de l’entreprise et les progrès technologiques. Il s’agit d’un changement de paradigme qui encourage l’agilité et l’évolutivité dans la gestion des données. Bien que l’adoption d’une architecture de maillage de données puisse présenter des défis, les avantages potentiels en termes d’agilité, d’innovation et de résilience en font un investissement rentable pour les organisations souhaitant exploiter pleinement leur potentiel en matière de données.
“Data Mesh est une approche sociotechnique décentralisée pour la gestion et l’accès aux données analytiques à grande échelle.” Zhamak Dehghani
Glossaire du Data Mesh
- Data Mesh (Maillage de données) : Une approche architecturale décentralisée pour la gestion des données à grande échelle.
- Propriété des données orientée domaine : Principe où les équipes spécifiques à un domaine sont responsables des données qu’elles produisent et utilisent.
- Infrastructure de données en libre-service : Outils et plateformes permettant aux équipes de domaine de gérer leurs données de manière autonome.
- Données en tant que produit : Concept traitant les données comme des produits à part entière, avec leurs propres cycles de vie et valeurs.
- Gouvernance des données fédérée : Approche de gouvernance où les équipes de domaine définissent leurs propres politiques tout en respectant les normes organisationnelles.
- API-first : Approche privilégiant la création d’API pour l’accès et l’intégration des données entre les domaines.
- Qualité décentralisée des données : Responsabilité des équipes de domaine pour assurer la qualité de leurs propres données.
- Architecture évolutive : Conception flexible permettant à l’infrastructure de données de s’adapter aux changements des besoins de l’entreprise.
- Résilience des entreprises : Capacité d’une organisation à s’adapter et à survivre face aux perturbations.
- Convergence des données : Processus d’intégration et d’harmonisation des données provenant de différentes sources.
- Silos organisationnels : Isolation des équipes ou des départements qui entrave la collaboration et le partage d’informations.
- Données structurées : Données organisées selon un format prédéfini, généralement stockées dans des bases de données relationnelles. Elles sont facilement recherchables et analysables (ex: tableurs, bases de données SQL).
- Données semi-structurées : Données qui ont une certaine structure organisationnelle, mais qui ne sont pas aussi rigides que les données structurées. Elles peuvent contenir des balises ou des marqueurs pour séparer les éléments (ex: fichiers XML, JSON).
- Données non structurées : Données qui n’ont pas de structure prédéfinie et ne sont pas organisées de manière prédéterminée. Elles sont plus difficiles à analyser et à traiter avec des méthodes traditionnelles (ex: texte libre, images, vidéos).
- Traitement par lots : Méthode de traitement des données où un grand volume de données est collecté sur une période, puis traité en une seule fois. Utilisé pour des tâches qui ne nécessitent pas de résultats en temps réel.
- Traitement en continu : Approche de traitement des données où les données sont traitées dès leur arrivée, permettant des analyses et des réactions en temps quasi réel.
- Traitement de flux : Méthode de traitement des données en continu, spécialement conçue pour gérer des flux de données en temps réel. Elle permet d’analyser et de réagir aux données au fur et à mesure qu’elles arrivent, sans nécessairement les stocker de manière permanente.
Dr Maguy Medlej, consultante senior en stratégie data