1. Une brève introduction au MLOps
A) Pourquoi le MLOps
D’une façon très générale le MLOPS est la pratique émergeante consistant à industrialiser la production de modèles de Machine Learning (ML). La production d’un modèle de Machine Learning se fait de manière très artisanale, notamment lorsque la volumétrie des données est peu élevée. La méthode de travail du Data Scientist consiste en général à :
- Récupérer les données dont il a besoin sur son poste
- Tester des modèles sur un Notebook
- Sauvegarder les indicateurs de performance sur un fichier Excel
- Communiquer le modèle aux développeurs et DevOps pour qu’ils puissent le mettre en production
- Vérifier si le modèle en production se comporte comme ce qui était attendu via des requêtes en base de données
Toute cette mécanique peut fonctionner si l’on travaille seul sur son projet en espérant ne jamais rencontrer de problème ; mais dès qu’il faut travailler en équipe, que l’on doit gérer des centaines d’algorithmes, que le poste de travail du Data Scientist ne démarre plus, ou que ce dernier quitte l’entreprise, cette mécanique atteint vite ses limites.
Des exemples de questions qui peuvent alors se poser :
- Quelle est la dernière version des données à utiliser ?
- Où sont passées les données que l’on a passé tant de temps à labelliser ?
- A-t-on déjà testé tel ou tel algorithme ? Si oui comment ? Avec quels résultats ?
- Quel est le Notebook qui a permis de générer le modèle ? Est-il un minimum structuré pour qu’il soit lisible et maintenable ?
- Comment faire pour savoir si le modèle fonctionne correctement en production ?
Des processus bien définis peuvent palier à certaines problématiques mentionnées ci-dessus, mais des outils peuvent également aujourd’hui faciliter le quotidien des Data Scientists.

B) Le MLOPS chez Twister
Chez Twister, la DSI de Davidson, nous travaillons sur divers projets de Machine Learning parmi lesquels on peut citer :
- Un chatbot disponible sur la page d’accueil du site web de Davidson https://www.davidson.fr/
- Un moteur de recommandations qui affiche un fil d’actualité personnalisé sur notre Intranet
Nous n’utilisions pas jusqu’à aujourd’hui d’outil dédié au MLOps c’est pourquoi nous avons décidé de réaliser une étude d’opportunité visant à :
- Savoir ce qui a déjà été testé, comment, avec quels résultats, afin de pouvoir partager simplement ce qui a été fait et faciliter la collaboration entre les Data Scientists
- Pouvoir rejouer des expériences passées, ce qui est très utile lorsque l’on souhaite repartir d’un projet, ou d’un test précédent afin d’avoir une baseline et de ne pas perdre de temps à tenter de la reproduire
- Stocker des modèles trop volumineux pour Git (la limite étant de 100Mb, et les modèles de traitement de la langue ou de traitement d’image pouvant facilement dépasser cette taille)
- Automatiser le ré-entrainement de modèles
Nous avons donc décidé de réaliser un Proof Of Concept en se basant uniquement sur des technologies open source pour industrialiser nos projets de Data Science.
Note : Nous n’avons pas abordé la partie déploiement, car chez Twister cette partie est déjà automatisée grâce à Gitlab-CI/CD et OpenShift.
2. Les solutions de MLOps
Il existe de plus en plus de solutions et il n’est pas forcément simple de faire le tri. Pour s’en rendre compte il suffit de consulter le site https://landscape.lfai.foundation
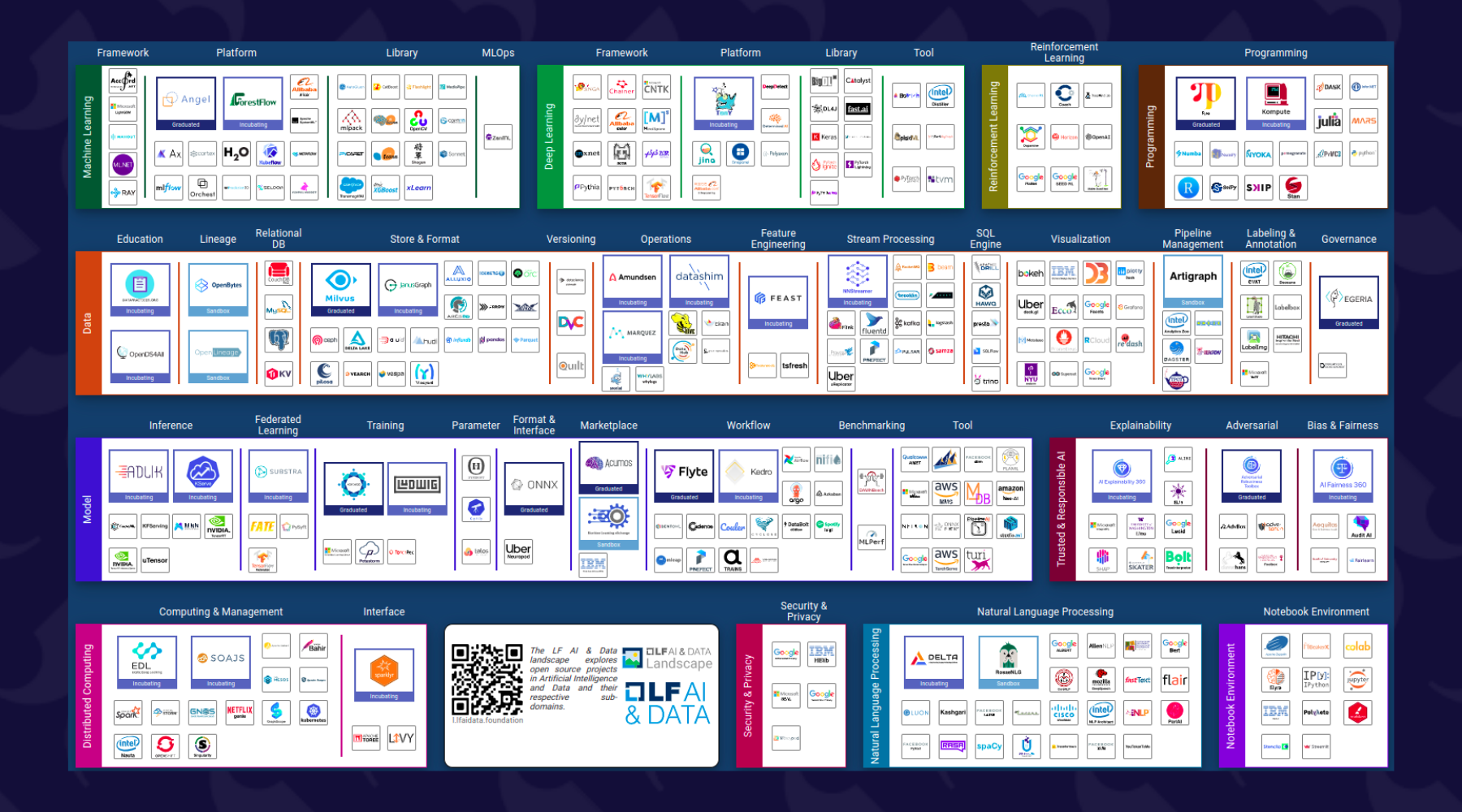
Certaines solutions couvrent plusieurs besoins d’autres se concentrent sur un sujet spécifique.
Après une première analyse sur les projets open sources nous avons choisi de tester les outils suivants :
- Des outils plutôt généraux : MLflow, Metaflow et KubefLow
- Des outils dédiés à la gestion des pipelines et de workflow : Airflow et Prefect
- Des outils dédiés au versioning des données : Pachyderm et DVC
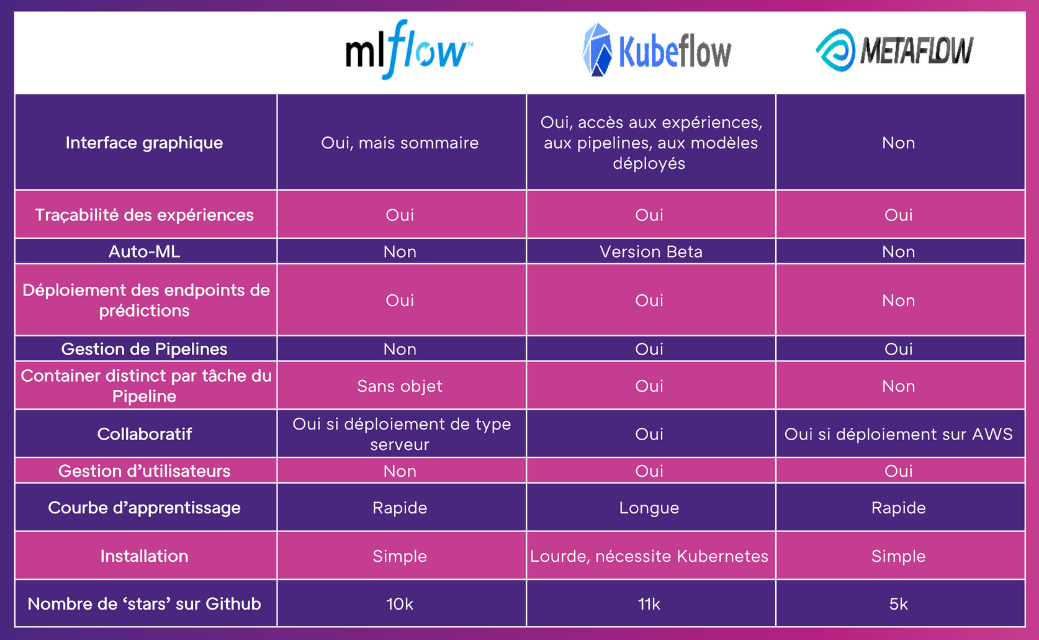
A) MLflow & Kubeflow & Metaflow
MLflow est une plateforme développée par Databricks qui permet de gérer une grande partie du cycle de vie d’un projet de machine learning.
Elle propose différents modules :
- Un module pour tracer les expériences
- Un module pour structurer le code de son projet
- Un registry de modèles
- Un module pour déployer ses modèles
Kubeflow est une plateforme de MLOps dévelopée par Google qui se base sur une architecture Kubbernetes. Elle permet principalement :
- De gérer des pipelines de machine learning
- De stocker chacun des artefacts des sorties des taches pour faire du tracking d’expérience
- De déployer ses modèles
Finalement Metaflow est une solution développée par Netflix qui permet d’organiser son code sous forme de pipelline et de tracer les expériences.
Ci-dessous un tableau comparatif de ces trois solutions :
B) Airflow & Prefect
Il s’agit de 3 outils qui permettent de gérer des pipelines qu’il s’agisse de Machine Learning ou non.
Le plus connu est Airflow, qui est largement utilisé dans les organisations qui ont besoin de gérer de nombreux pipelines. L’interface graphique est claire, il est possible de consulter les pipelines, de relancer des taches en échec, de les planifier… Cependant il est lourd à déployer (il nécessite un serveur pour l’interface web et un serveur pour le scheduler) et le développement des pipelines n’est pas intuitif.
Prefect a été créé par un des fondateurs d’Airflow dont le but était de simplifier l’outil. La création de pipeline est effectivement très facile, de plus seule l’installation du package Python est nécessaire. Il est aussi possible de déployer un serveur pour tracer les exécutions des pipelines et une interface graphique. A noter qu’il existe une version entreprise avec des fonctionnalités supplémentaires comme la gestion des utilisateurs.
C) Pachyderm & DVC
Il s’agit d’outils pour versionner les données et pour structurer son code sous forme de Pipelines.
Pachyderm est très puissant car il ne stocke que les différences entre deux versions du même dataset. Si une modification est faite sur le dataset le pipeline est automatiquement relancé. Autre point intéressant, si l’on modifie une tâche du pipeline, seule cette tâche et les suivantes seront réexécutées. Il existe aussi une interface graphique mais cette dernière est payante depuis 2018.
DVC permet lui aussi de versionner des datasets volumineux, son point fort c’est sa simplicité d’utilisation. En effet DVC reprend la syntaxe de Git pour versionner les datatasets et les récupérer. Le bémol est que pour chaque version DVC stocke l’entièreté des datasets et pas uniquement les différences.
3. Les solutions de MLOPS dans notre contexte
Notre équipe de Data Science est constituée de quelques personnes et nous intervenons sur un nombre restreint de projets. Nous cherchons donc avant tout une solution facile à mettre en œuvre, simple à exploiter, et avec une courbe d’apprentissage rapide. Ce dernier point est fondamental car l’équipe évolue constamment (stagiaires, inter-contrats…). La communauté autour des projets, leur activité, et le fait qu’ils ne soient pas payants à moyen terme a aussi été pris en compte.
Nous avons alors opté pour la stack suivante :
- MLflow pour le tracking des expériences et le Model registry
- DVC pour le versioning des données
- Prefect pour la gestion des pipelines
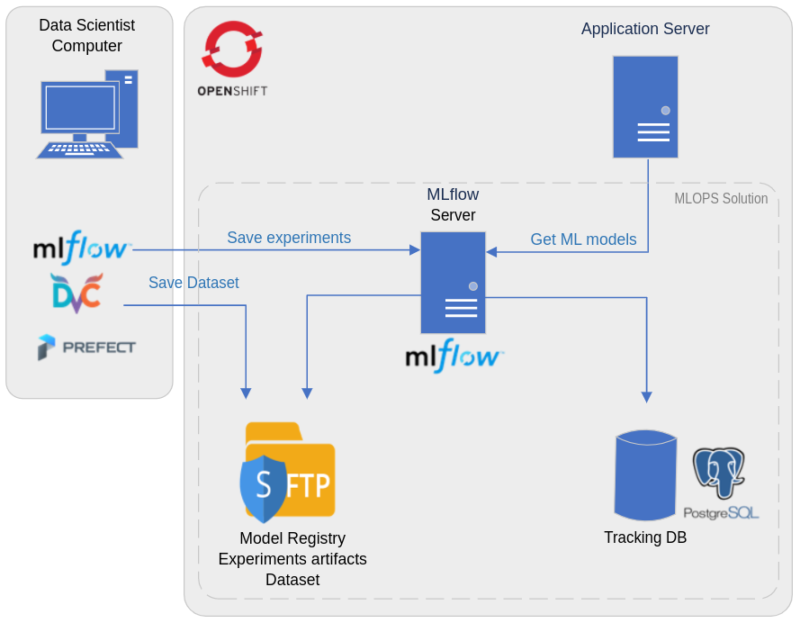
A) Architecture
D’un point de vue architecture technique tous les containers nécessaires à la solution sont gérés sous OpenShift, avec :
- Un container pour le server MLflow
- Un container pour la base de données PostgreSQL qui sert à stocker les métriques et les paramètres de chacune des expériences
- Un container SFTP pour le stockage des artifacts des expériences (comme des images liées aux résultats des expériences), le stockage des modèles, et le stockage des datasets
B) Méthodologie de travail
La méthodologie de travail des Data Scientist a été revue pour profiter au maximum des fonctionnalités proposées par ces outils. L’élément central à la nouvelle méthodologie est le Git commit. En effet sur chaque expérience le Git commit doit être référencé, il est ainsi très facile de retrouver le code qui l’a produite. De plus grâce à DVC, un petit fichier référençant les données utilisées est aussi ajouté sur Git. Le Data Scientist peut ainsi aussi retrouver les données sans se poser de question.
Etape 1 – initialisation du projet
Pour repartir d’un projet existant le Data Scientist à simplement besoin de lancer les deux commandes suivantes pour récupérer tout ce dont il a besoin :
$ git clone projet
$ dvc pull
Si le Data Scientist souhaite partir d’un précédent test, il lui suffit de récupérer depuis MLflow le numéro de commit adéquate, et de lancer les commandes suivantes :
$ git checkout -b new_branch commit_number
$ dvc pull
Le Data Scientist a ainsi le code et les données pour reproduire la baseline. Les versions des packages utilisés sont aussi importantes, ces dernières sont stockées sur MLFlow.
Etape 2 – Réalisation de nouveaux tests
Le Data Scientist peut ensuite réaliser de nouvelles expériences.
- Si la modification concerne du code (génération des features, nouveau modèle, nouvelle façon de spliter les données), alors cette modification doit faire l’objet d’un commit avant de lancer l’entrainement. Il est aussi possible de faire des commit automatiques pour alléger le processus en utilisant le package GitPython
- Si la modification concerne des paramètres du modèle, qui sont tracés par MLFlow, il n’est donc pas nécessaire de réaliser de commit
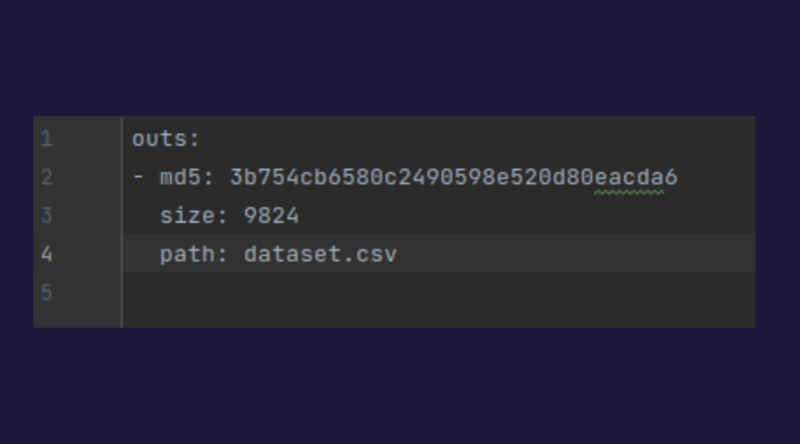
- Si la modification concerne le dataset le Data Scientist doit uniquement lancer la commande : dvc add dataset
Cela génère un petit fichier suffixé .dvc dont voici un exemple et qu’il faudra commiter.
De plus le dataset est automatiquement uploadé sur le serveur SFTP.
Etape 3 – Consulter les résultats sur MLFlow
Les résultats sont visibles sur MLFlow et peuvent être comparés avec les résultat obtenus précédemment.
Ci-dessous l’écran d’accueil de MLflow où l’on peut accéder à l’ensemble des expériences menées.
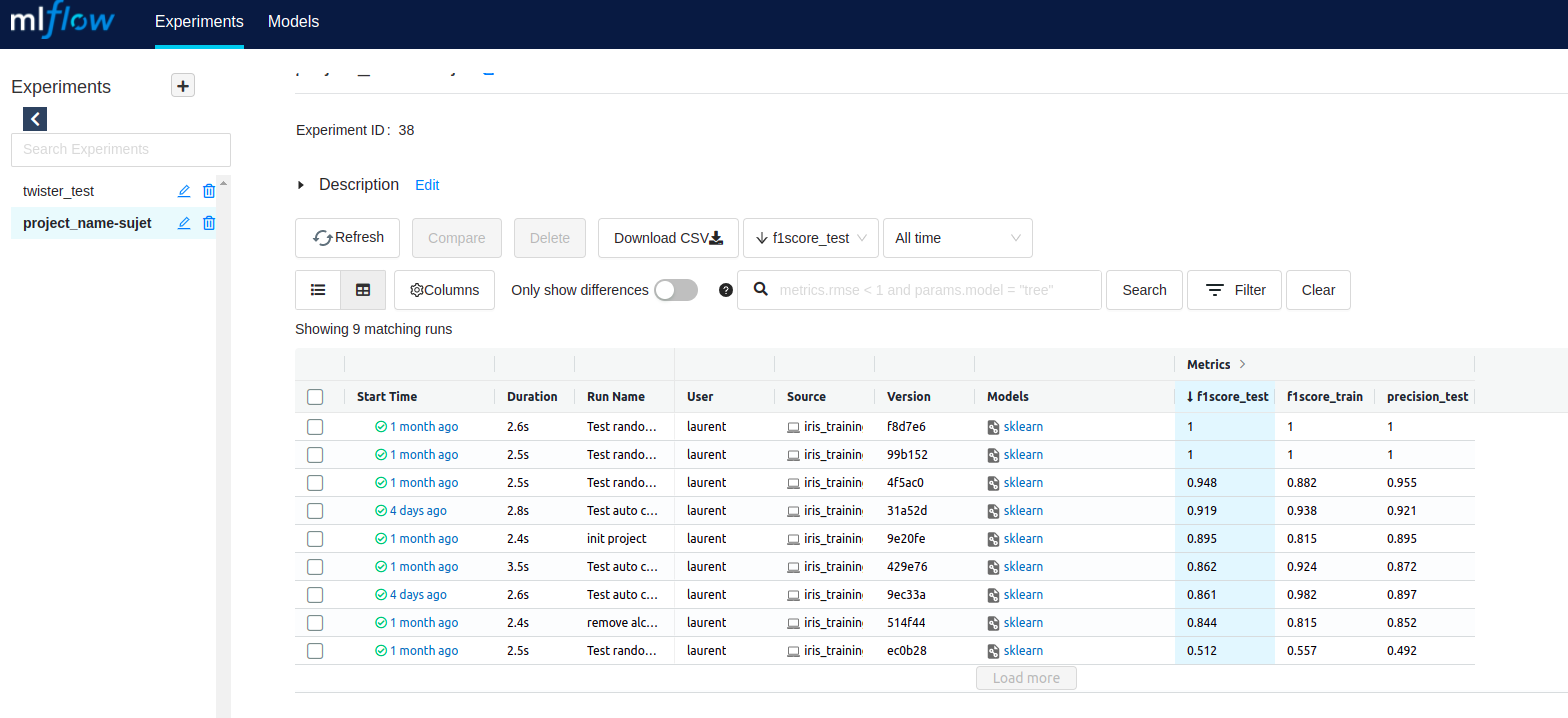
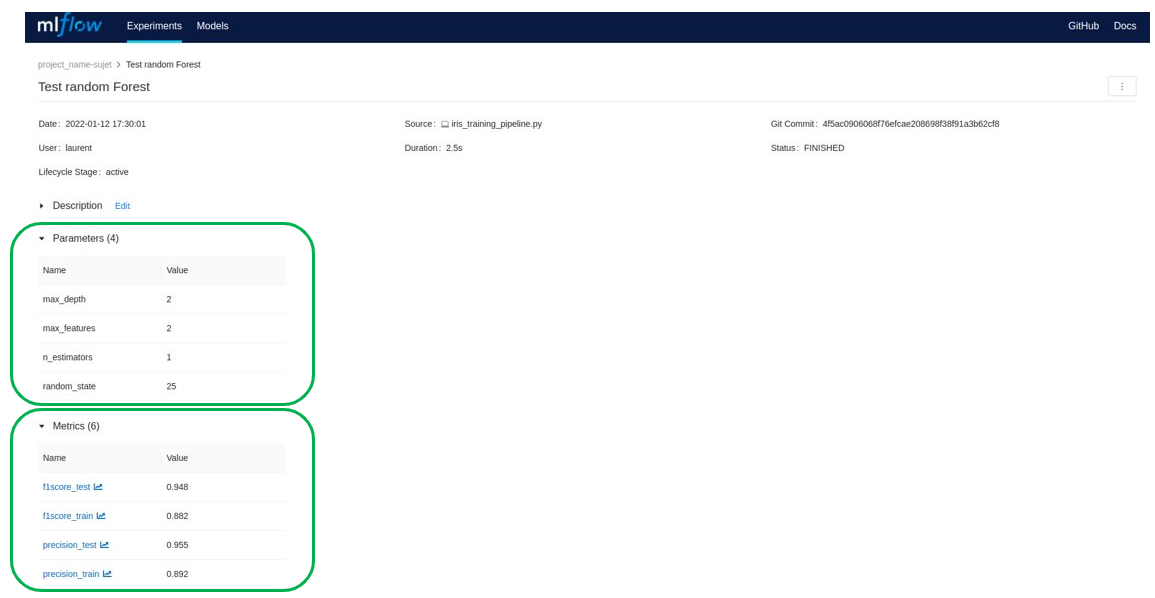
Il est possible de consulter le détail d’une expérience : les paramètres, les résultats, les package python utilisés…
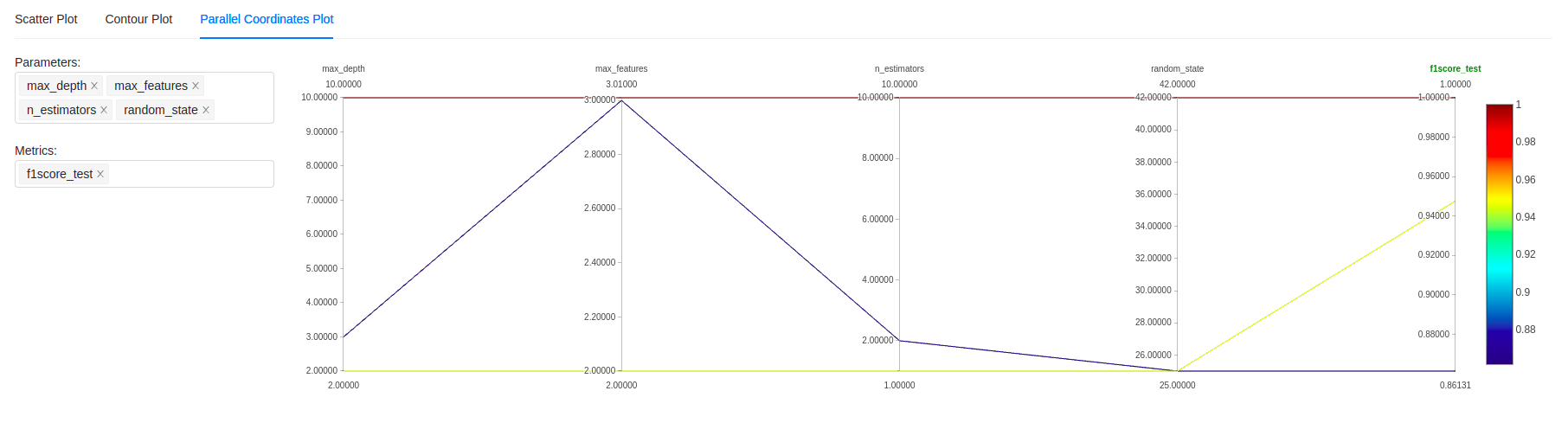
Il est aussi possible de comparer plus finement des expériences en utilisant différents types de graphes dont le classique “parallel coordinate plot” que l’on peut voir ci-dessous :
Etape 4 – Générer le modèle de production
Si les tests ont été probants, il faut alors générer le modèle de production en commitant les modifications de codes nécessaires puis en traçant le résultat final.
Le modèle doit alors être enregistré sur le registry des Modèles en passant par MLflow.
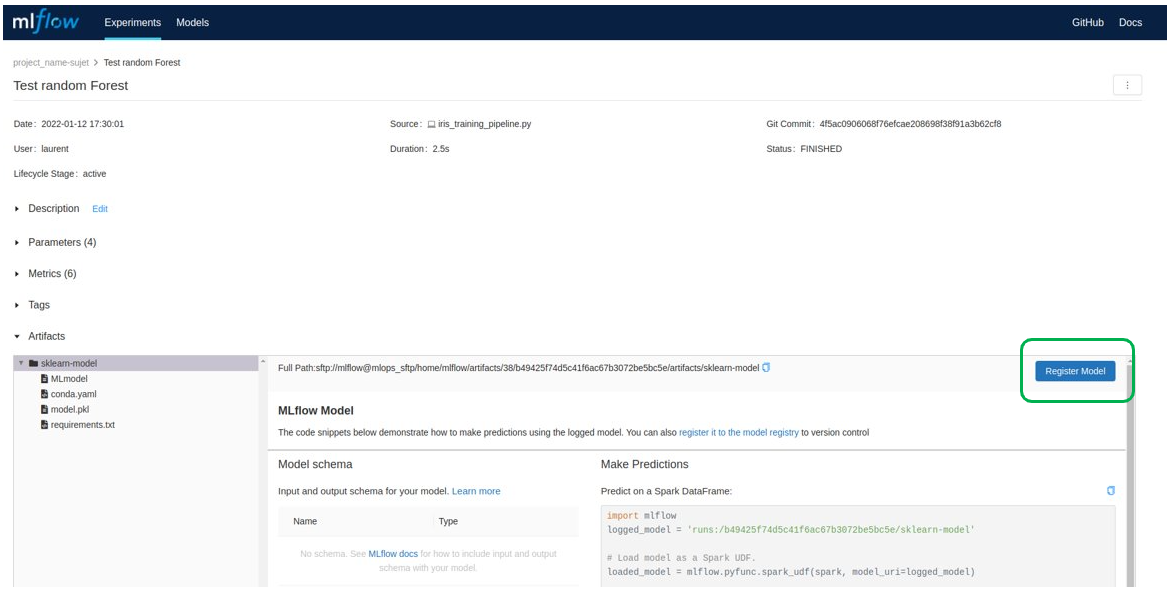
Il pourra ainsi être chargé dans le code en utilisant l’API MLFlow. Le modèle et le code nécessaire à son fonctionnement doivent alors être intégrés au code de production.
C) Focus sur l’utilisation des nouveaux package
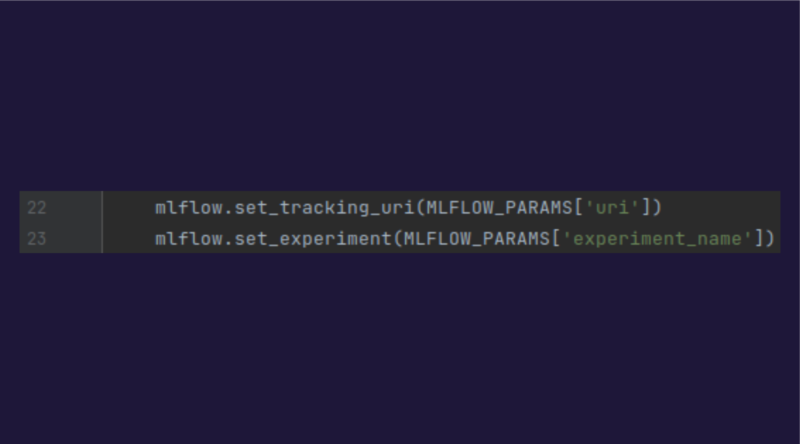
1.MLFlow
Pour utiliser MLflow il faut initialiser l’environnement MLFlow en indiquant l’uri du serveur MLflow, ainsi que le nom de l’expérience.
On peut ensuite tracer aisément ce que l’on souhaite en utilisant les méthodes appropriées :
- mlflow.log_params
- mlflow.log_metrics
- mlflow.sklearn.log_model
- …
C’est donc extrêmement simple de tracer tout ce que l’on souhaite.
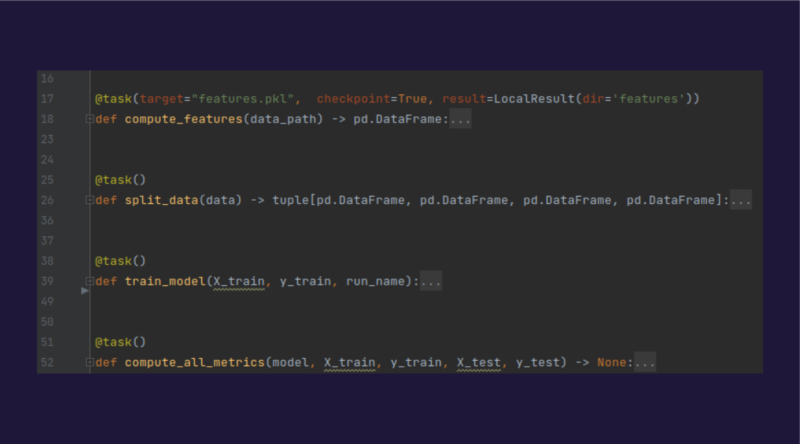
2.Prefect
L’utilisation de Prefect dans notre contexte permet surtout de structurer le code, pour faciliter la maintenance et les réentrainements de modèles.
Chaque entrainement est découpé en tâches, chacune correspondant à une fonction, et l’ensemble va constituer un pipeline.
Pour créer une tâche il suffit de décorer la fonction que l’on souhaite via le décorateur “@task”
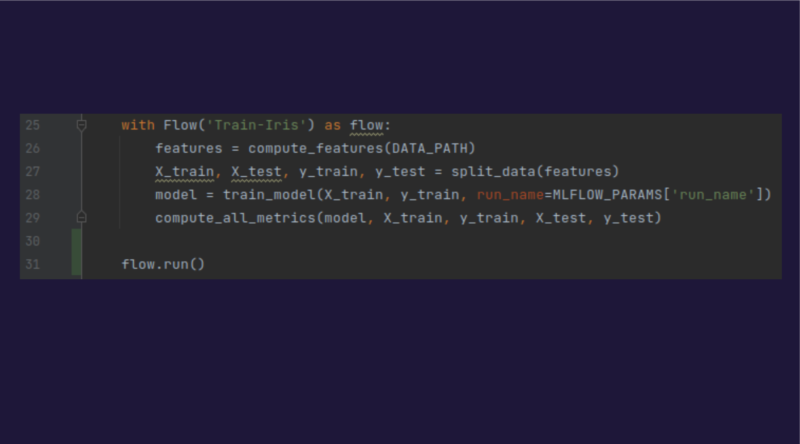
Pour créer le pipeline il suffit alors de créer un “context manager” qui va enchainer les tâches, et de l’exécuter.
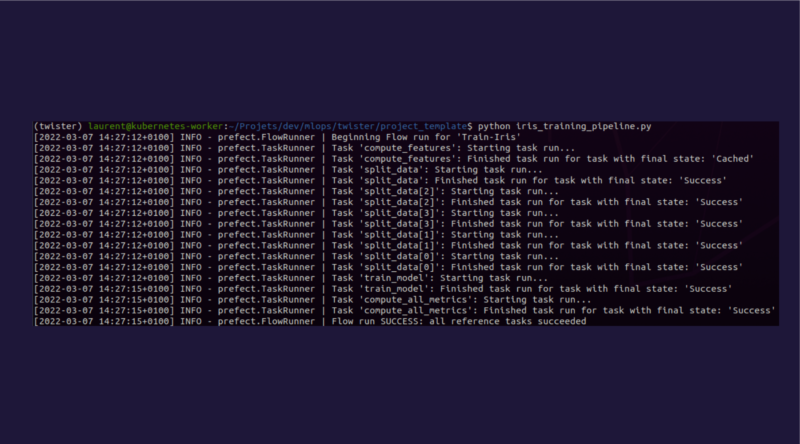
Il ne reste plus qu’à lancer le script Python correspondant.
4. Comparatif des coûts
Il est intéressant de comparer les coûts dans les 3 scénarios sans industrialisation, avec la solution que nous avons prévue, et en utilisant une solution du Cloud.
1. Sans industrialisation
Dans le cas où il n’y a aucune industrialisation, les coûts sont surtout générés par le temps perdu par les Data Scientists dans leurs tâches au quotidien :
- Saisir manuellement les scores, et metadata des entrainements
- Essayer de reproduire la baseline du projet ou les derniers résultats qui correspondent au modèle actuellement en production
- Tester des algorithmes qui ont déjà été testés précédemment
- Gérer manuellement les datasets pour les sauvegarder dans un espace partagé et backupé
- Ré-entrainer manuellement les modèles
- …
Il est difficile d’estimer le nombre de jours perdus par an, tout dépend du contexte et des types de projets… Cependant il est légitime de penser que c’est une réelle perte de temps qui devrait plutôt être consacrée à des tâches qui apportent de la valeur : veille, amélioration des modèles, amélioration du code…
2. Avec une industrialisation “maison”
Les coûts liés à la mise en place de la solution maison telle que décrite précédemment s’étalent sur plusieurs postes :
Un coût initial qui correspond à :
- La mise en place de l’architecture technique de la solution sous OpenShift, que l’on estime à 3 jours
- L’adaptation du code des projets existants, que l’on estime à 5 jours par projet (cela dépend bien entendu de chaque projet)
Puis les coûts de fonctionnement qui correspondent à l’administration, l’exploitation de la solution, que l’on estime à 10 jours par an, et les coûts liés à l’hébergement et à Openshfit que l’on estime à 1500€ par an.
3. Avec une solution Cloud
Avec une solution Cloud, il y a comme précédemment les coûts liés à l’adaptation du code des projets existants.
Puis il y a les coûts mensuels liés aux outils de Machine Learning qui varient d’un fournisseur à l’autre ; si l’on prend l’exemple du ML Studio d’Azure, avec 4 vCPU et 16Go de Ram, cela revient à 192$ par mois par Data Scientist d’après https://azure.microsoft.com/en-us/pricing/calculator/ (sans compter les frais de stockage, de réseau, etc…).
5.Conclusion
L’outil préféré des Data Scientist a longtemps été le Notebook qui s’il est utilisé sans rigueur peut vite devenir désordonné et faire exploser la dette technique.
Les outils de MLOps permettent de cadrer le travail du Data Scientist et au final de lui faciliter la vie ; il est vrai que cela demande un coût initial pour migrer les projets et mettre en place l’infrastructure adéquate, mais les gains potentiels derrière sont importants : mieux tracer pour mieux comprendre pour mieux optimiser ses modèles, sans parler des gains sur la maintenabilité des projets et sur le travail en équipe.